哈喽,大家好呀,我是呼噜噜,今天我们来了解一下"什么是TCP 的粘包和拆包", 这是一个非常经典且重要的面试知识
什么是"粘包"和"拆包"?
那在计算机网络中,到底什么是粘包/拆包现象?
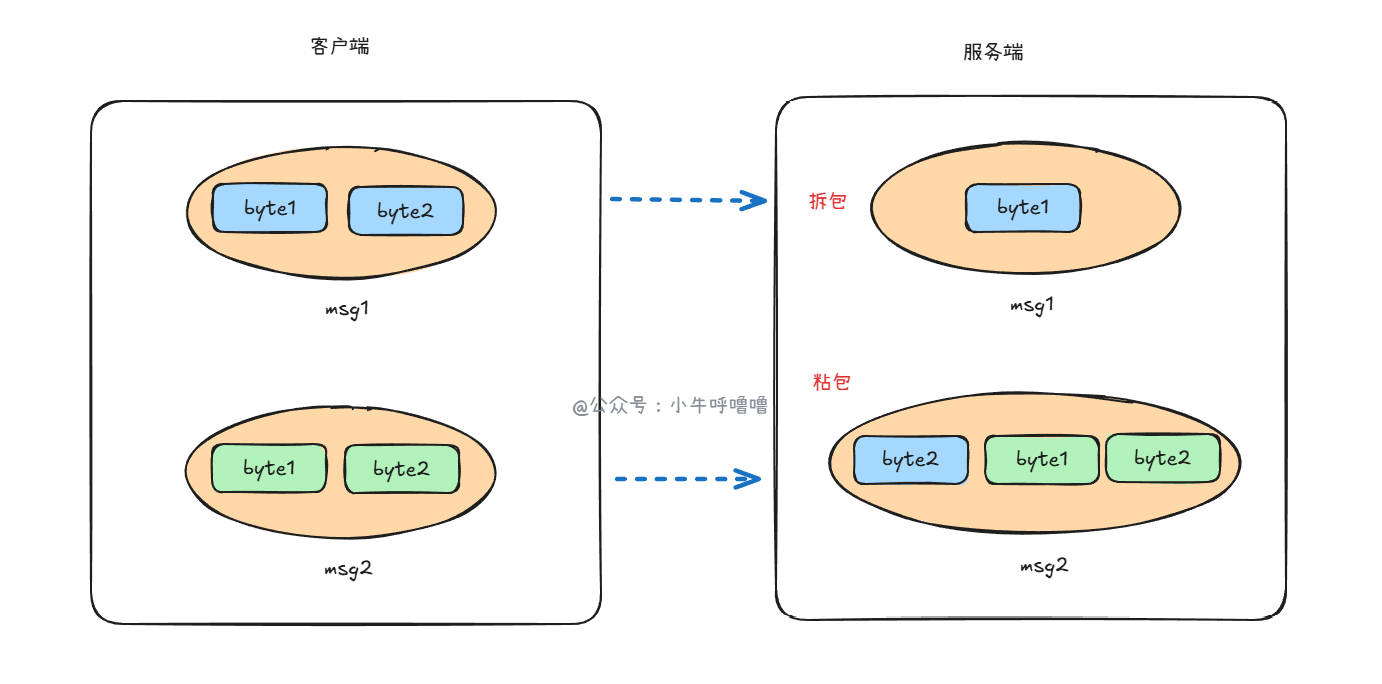
我们这里举个小例子,假设客户端连续发送两个数据包:D1 和 D2
正常情况: 服务端分两次读取,第一次读到 D1,第二次读到 D2。
粘包(Sticky Packet): 服务端一次读取到了 D1 + D2 粘在一起的数据。比如:D1D2。这时候服务端应用程序无法直接区分原始消息边界,不知道哪里是 D1 的结束,哪里是 D2 的开始。
拆包(Split Packet):服务端第一次读到了 D1 的一部分;第二次读到了 D1 的剩余部分 + D2。这通常是因为包太大或者网络传输限制导致的
通俗点讲,我们可以把TCP 想象成一根水管,数据像水一样流过去,没有自然的边界。发送端发的“两杯水”,接收端可能一下子接到了“一大桶水”(粘包),或者分了好几次才接满(拆包)。
为什么会发生这种情况?
TCP 是为可靠、顺序、无差错的字节流传输设计的,TCP传输的数据是以字节流Byte Stream的形式,而不是消息Message的形式。它只负责把字节准确地发送给对方,字节流是没有明确的开始结尾边界,所以TCP无法判断哪一段流属于哪一个消息
所谓流式Stream协议,与自带边界的消息Message协议不同,它提供的是无结构的字节流。应用层必须自行定义和实现消息边界的识别逻辑(如使用长度前缀或特定结束符)
"粘包"和"拆包"并不是TCP本身的Bug,产生粘包和拆包的主要原因有以下几点:
Nagle 算法:TCP为了提高传输效率,默认开启Nagle算法。如果发送端连续发送很多小的数据包,TCP不会立刻发送,而是把它们攒成一个大包一次性发出去。可能导致粘包- 写入速度过快: 应用层向
TCP发送缓冲区的写入数据速度 > 网络发送速度,导致多个数据包在缓冲区里连在了一起。可能导致粘包 - 读取滞后:
接收端的应用层读取缓冲区的速度 < TCP 接收数据的速度。缓冲区里堆积了多个包,应用层一次读取时就把它们全读出来了。可能导致粘包 - 协议中
MSS/MTU限制:如果应用层发送的一个数据包超过了MSS(TCP最大报文段长度),TCP就必须把它切分(拆包)成多块发送。可能导致拆包
所以同一消息可能被拆成多个 TCP 段(导致拆包),也可能多个消息合并到一个或多个段里(导致粘包),本质是TCP流模型和应用层消息边界不匹配导致的
UDP有没有"粘包"和"拆包"现象?
UDP协议没有这种现象,因为UDP才是面向消息的协议,它有消息保护边界,故不会发生粘包拆包问题
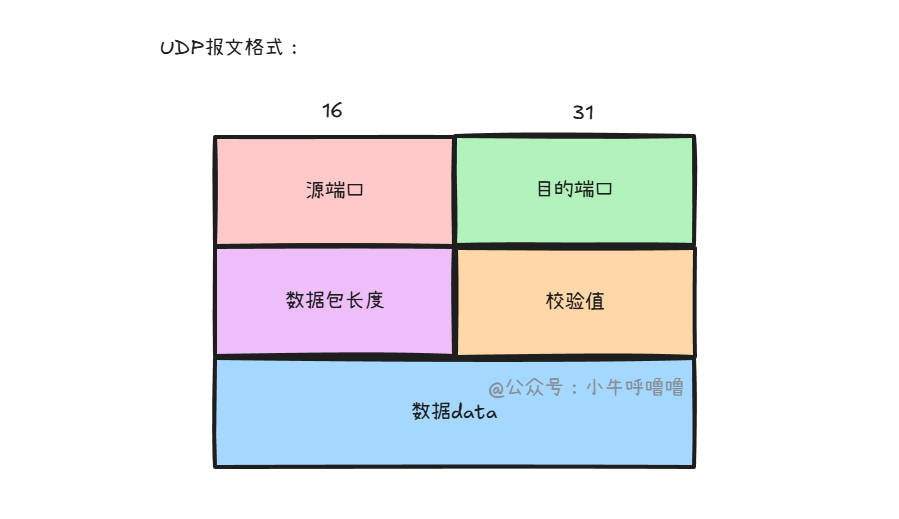
理解MTU与MSS
这里再补充一下文中的MSS与MTU概念:
- 最大传输单元(MTU,Maximum Transmission Unit)
- 它属于
数据链路层 - 表示 链路层一次能传输的最大字节数(含所有头部)
- 包含
IP头部、TCP/UDP头部、应用层数据(即 “整个数据包”) - 以太网默认
1500字节
- 最大报文段长度(MSS,Maximum Segment Size)
- 它属于
TCP传输层 - 表示
TCP报文段中数据部分的最大字节数(不含头部) - 仅包含
TCP协议承载的应用层数据(纯payload) - 通常为
MTU减去IP头部(20字节)和TCP头部(20字节),如1460字节
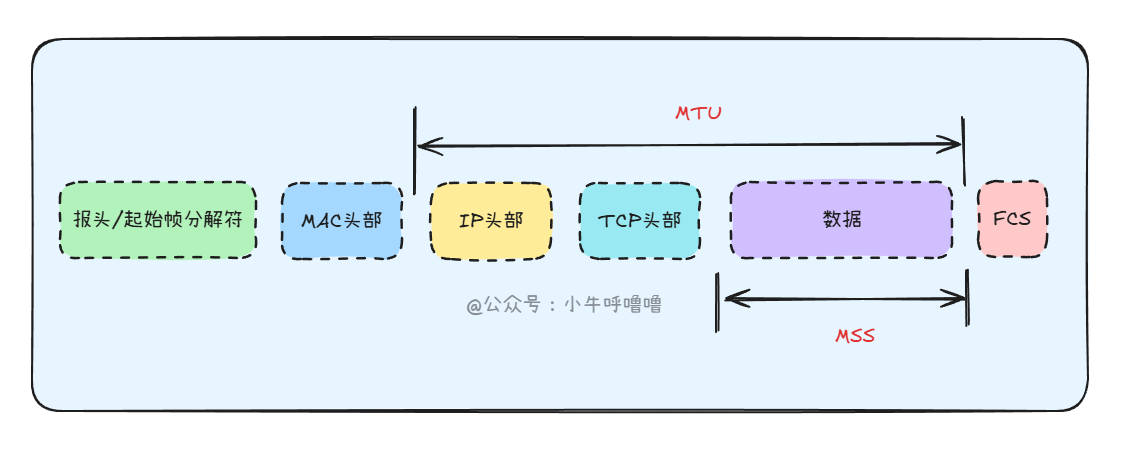
它们的作用如下:
- IP分片:当
IP数据包大小超过链路MTU时,IP层(也叫网络层)会将其拆分为多个小片段进行传输,这些片段在目的地重组 - TCP分段:
TCP在传输层就根据MSS将数据分割成合适的大小,使其封装后的IP包不超过MTU,从而尽量避免在IP层发生分片
如何解决粘包拆包?
既然TCP不做"消息边界",那我们就自己做!我们可以在应用层来定义"消息边界"
固定长度帧
我们可以使用固定长度帧(Fixed-length),规定每个业务报文的长度都是固定的(例如 100 字节)。无论实际内容多少,都补齐到 100 字节
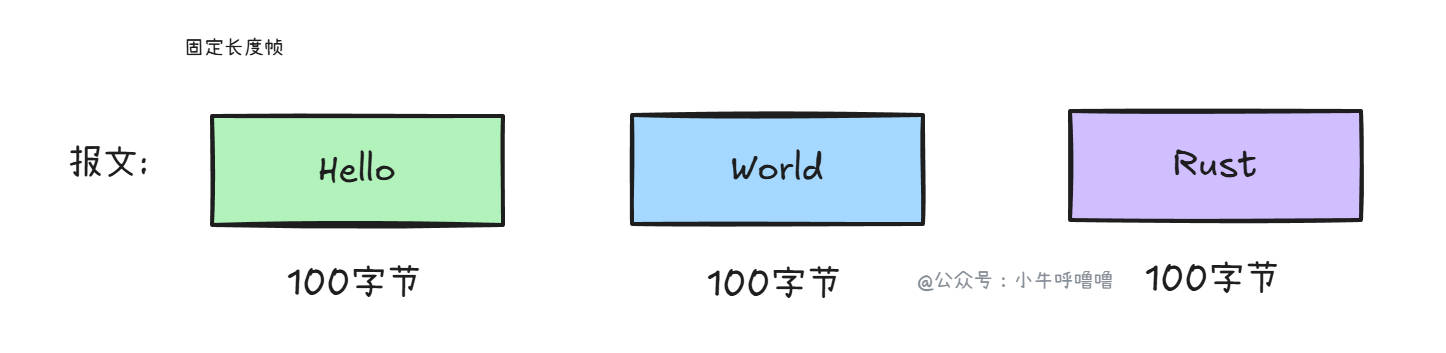
它的优点是:实现简单;缺点就是:浪费带宽/内存,因为填充了大量无用字符,如果消息只有 1 个字节,也要发 100 字节;不适合可变长消息,灵活性差
特殊分隔符
我们还可以使用特殊分隔符 (Delimiter Based),其实就是 在每个数据包的末尾添加特定的分隔符(如 \n、\r\n 或自定义的 $_$)。接收方通过寻找分隔符来切分包。
比较直观,接收端读到 \n 就认为是一条消息结束。HTTP/1.0 简单行式协议,文本协议、FTP 和 Telnet 协议常用这种方式
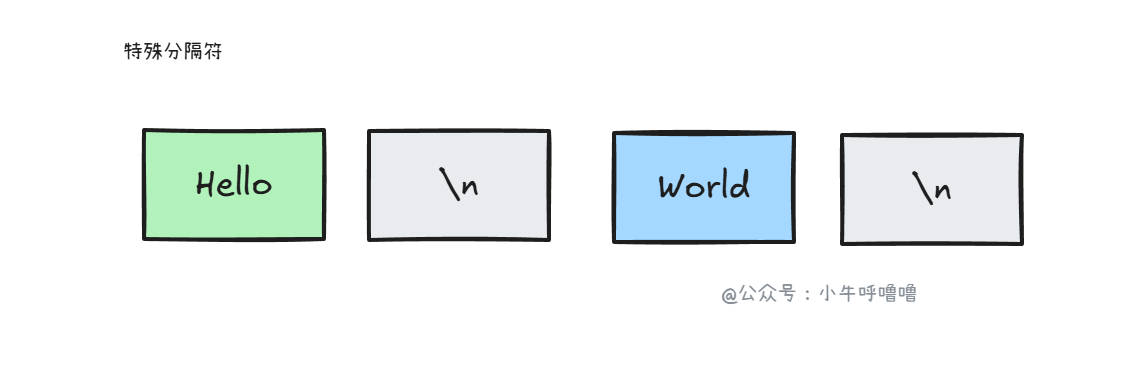
缺点就是:消息内容本身不能包含这个分隔符,否则需要转义,处理麻烦
消息头+消息体
这是最通用、最推荐的方案,就是消息头+消息体 (Length Field Based),在发送数据时,先发送一个固定长度的字段Header表示后续数据的总长度,然后再发送实际的数据Body。格式形如:[Header: 长度 4字节][Body: 实际内容]
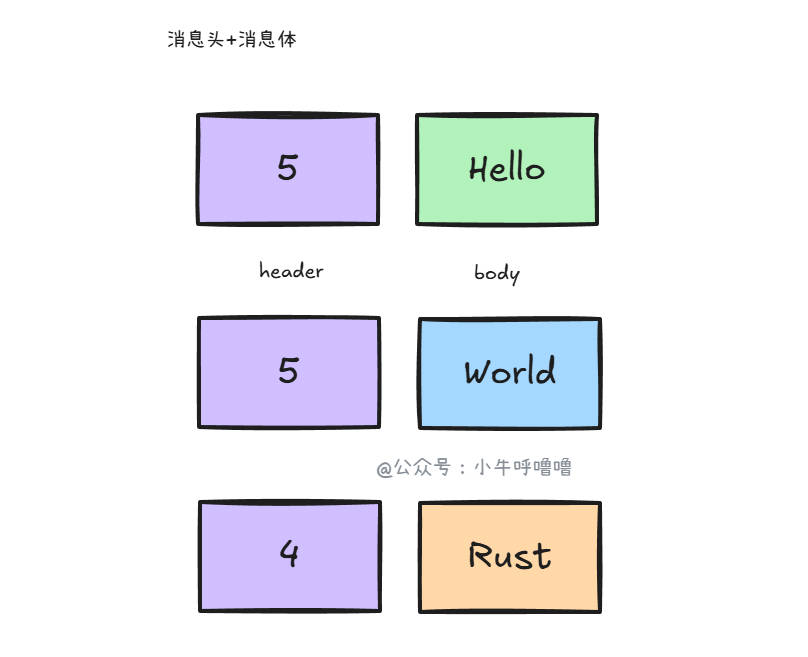
它的流程:
- 接收端先读取头部固定的
4个字节,解析出整数值(比如是1024)。 - 根据这个长度,继续往后读取
1024个字节。 - 读满后,这
1024个字节就是一个完整的包。
虽然设计略复杂,需要提前约定头部的格式和长度,但其优点:精准,支持变长消息,无歧义,可扩展(支持二进制)
它也是多数高性能二进制协议(gRPC、自定义二进制协议)常用方案。
更高级的应用层协议
我们还可以直接使用,已经解决该问题的应用层协议,直接站在巨人的肩膀上,如:
- HTTP:通过
Content-Length请求头来标明Body长度。 - Protobuf/Thrift:这些序列化框架通常都有自带的帧处理机制。
小结
本文我们解释了TCP的"粘包"和"拆包",当我们直接使用 TCP 编程(Socket 编程)或者自定义应用层协议,就会遇到该问题。我们必须明白,TCP 是字节流,不保证消息边界。应用层必须显式设计帧协议
如果你能看到这里,感谢阅读!关注我,获取更多学习干货!
作者:小牛呼噜噜
本文到这里就结束啦,感谢阅读,关注同名公众号:小牛呼噜噜,防失联+获取更多技术干货