哈喽,大家好,我是呼噜噜,好久没有更新了,在之前的一篇 文章:内存中堆和栈,到底有什么区别? 中,我们了解了内存中堆和栈,到底是什么,它们之间有什么区别?各位未来的黑客们,平时写程序,经常遇到函数调用吧,那么函数调用是究竟是怎么实现的呢?今天我们来聊聊这个经典的话题
编程语言中的函数调用,主要依赖栈和寄存器来实现,主要因为函数调用的特性,比如最后被调用的函数最先返回,正好遵循着栈的先入后出的原则
栈帧
栈stack是程序运行的基础。每当一个函数被调用时,操作系统在内存中的栈顶位置,分配一块连续的内存,这块连续的内存被称为栈帧frame
栈帧一般包含函数的参数、局部变量、返回地址以及保存的寄存器值等信息,具体如下:
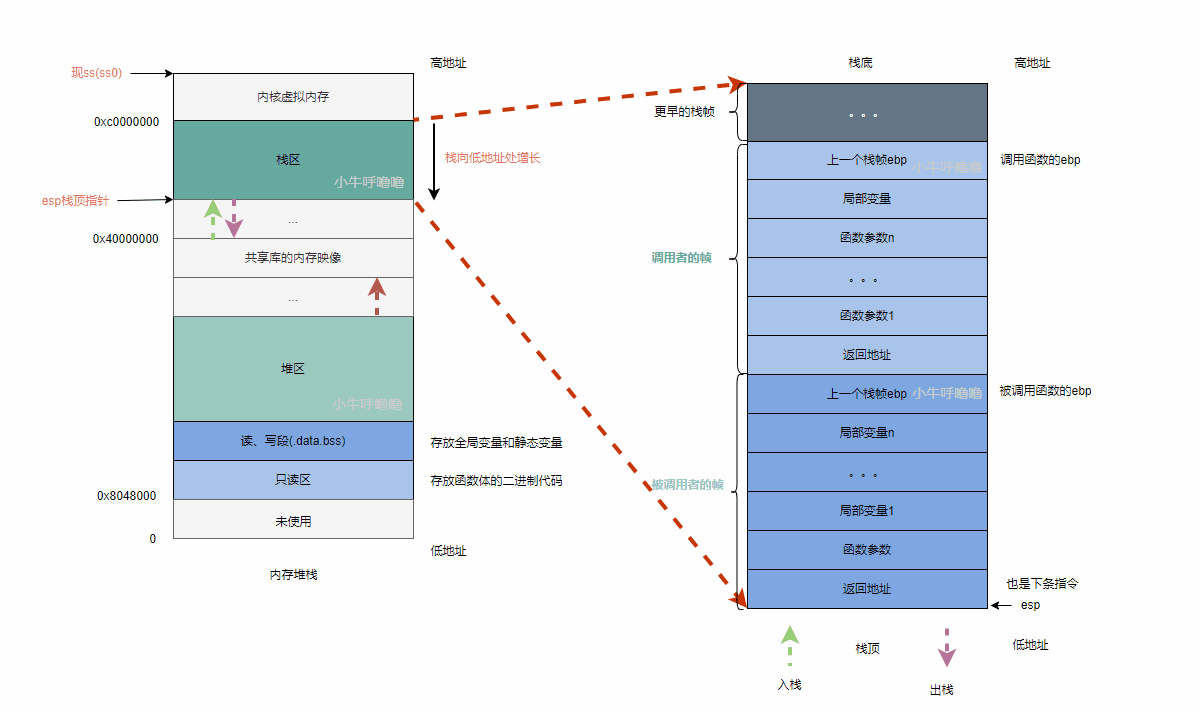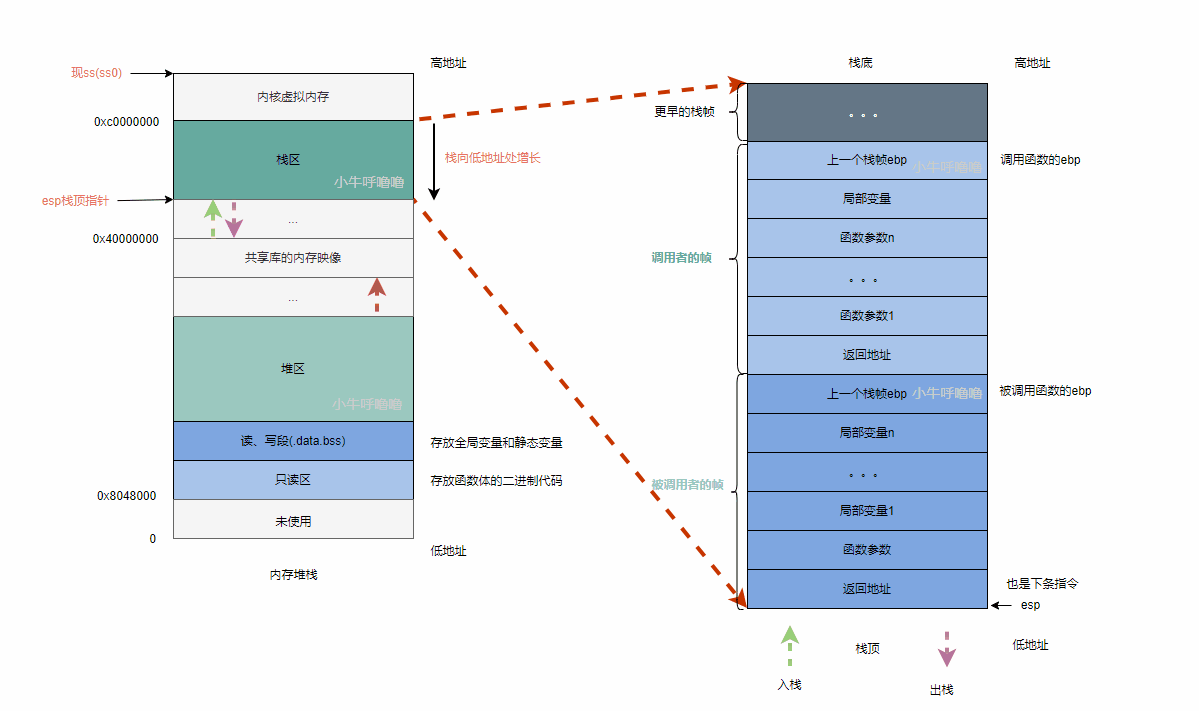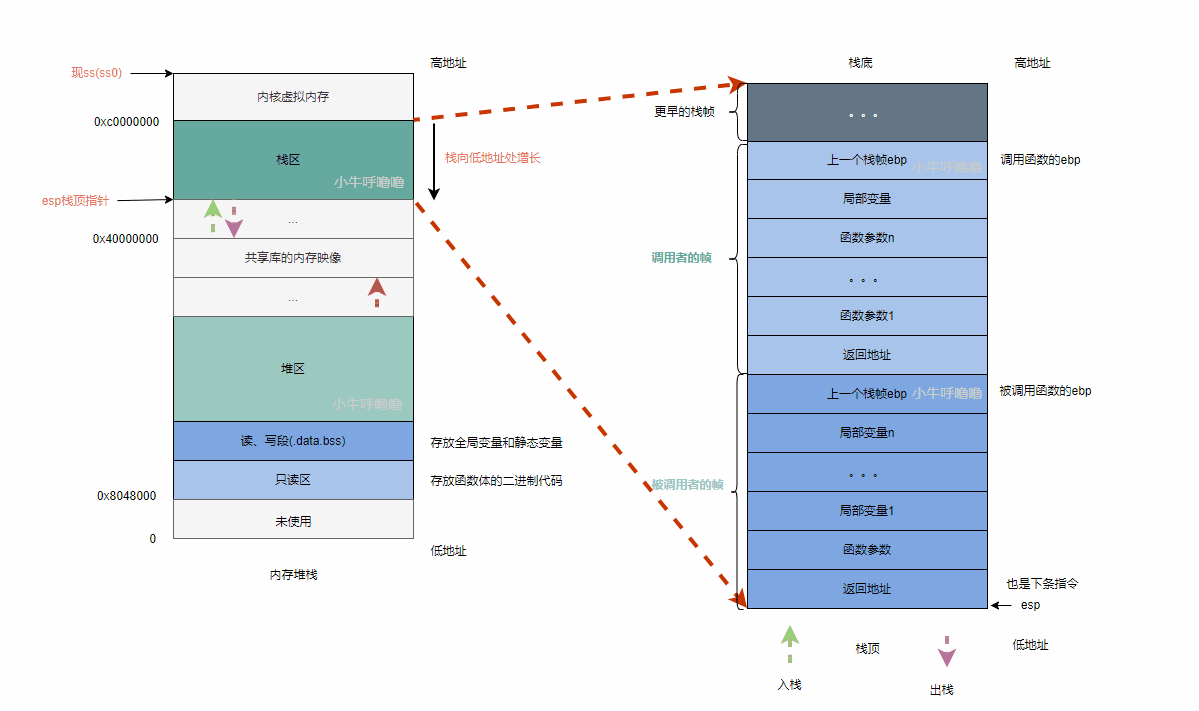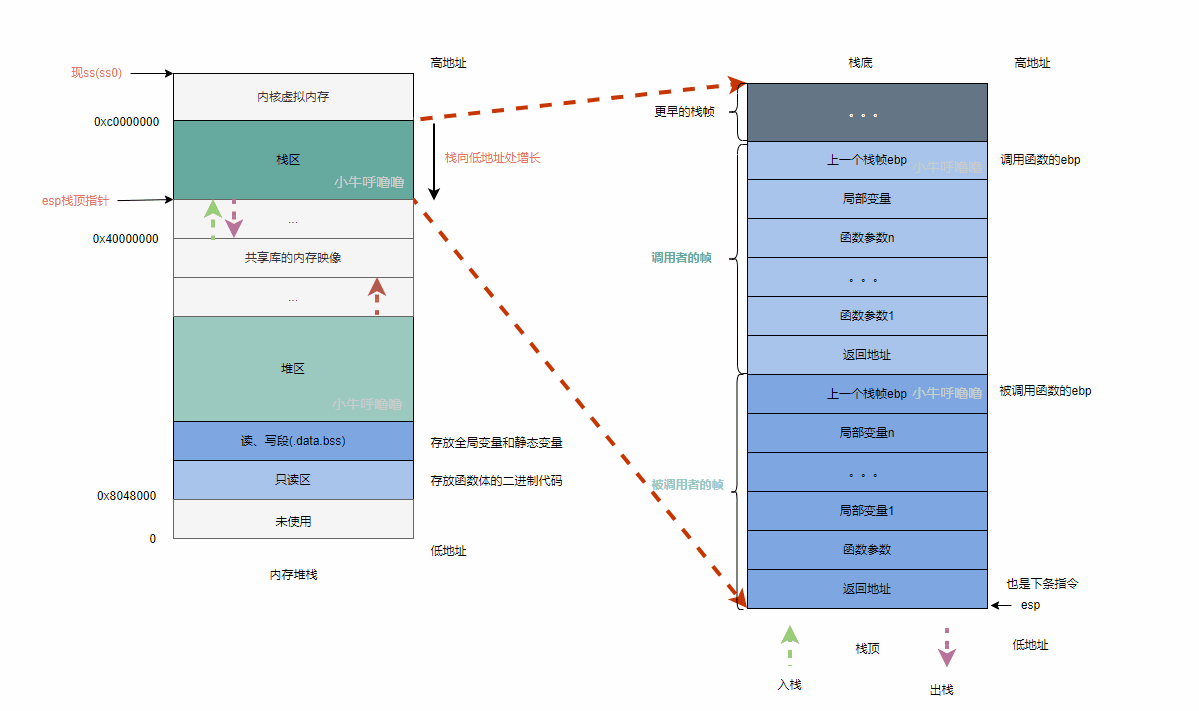
栈是从高地址往低地址方向生长的,高地址处为栈底,低地址处为栈顶,栈顶也是入栈出栈的地方。每当一个函数被调用时,内存中会创建一个独立栈帧
另外在x86的CPU中,栈帧的空间范围是通过 ebp 和 esp 这两个寄存器来共同管理划定的,ebp寄存器存放的是帧指针,指向当前的栈帧的底部;esp存放的是栈指针,始终指向栈的顶部
当程序执行,依次调用函数时,栈指针esp可以移动,会一直跟着栈顶,将esp指针存入esp寄存器中;而帧指针ebp是不移动的,ebp寄存器始终存放当前最新栈帧的ebp指针。要想访问栈中的元素,可以将ebp指针作为基准地址再加上偏移量,就能访问栈中的任一元素啦,比如%ebp+8、%ebp+4、%ebp -4、%ebp -8等等,以4字节为单位

栈由于是一段连续的空间,为了支持多线程,编译器一般不会给单一线程分配过多的栈内存,大约1MB~8MB;但一般栈内存都是够用的,倘若当定义一个非常大的数组时候,递归没有正确的终止条件或者函数调用层次太深,栈内存销毁殆尽,发生Stack Overflow错误
另外需要注意的是,在现代Linux下,一个进程中的所有线程共享该进程的地址空间,但它们有各自独立的(私有的)栈,栈上的数据都是被独占的,其它线程无法访问;不同的是,一个进程有一个运行时堆,进程中内的所有线程共享进程的堆
函数调用的顺序
每当一个函数被调用时,os都会在内存中创建一个独立栈帧,从栈顶压入,这个过程也被称为函数入栈;而当函数调用结束时,最后被调用的函数最先返回,相关的栈帧会依此从栈中弹出,这个过程被称为函数出栈
我们这里举个例子:3个函数方法依次调用
function fun_1() {
fun_2();
}
function fun_2() {
fun_3();
}
function fun_3() {
printf("...");
}- 函数入栈的顺序
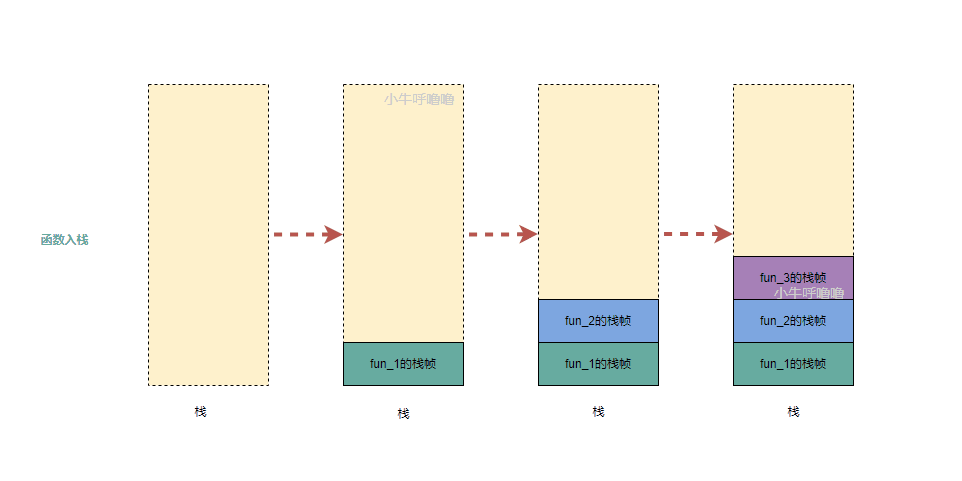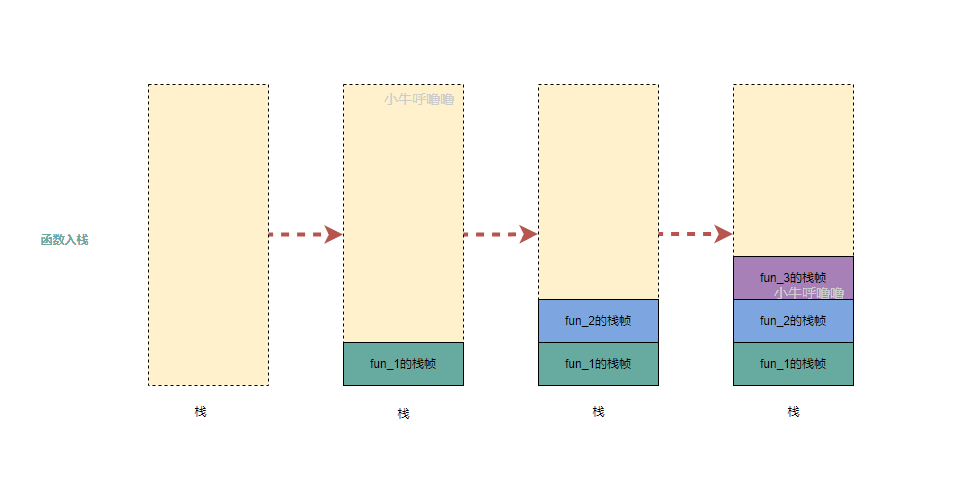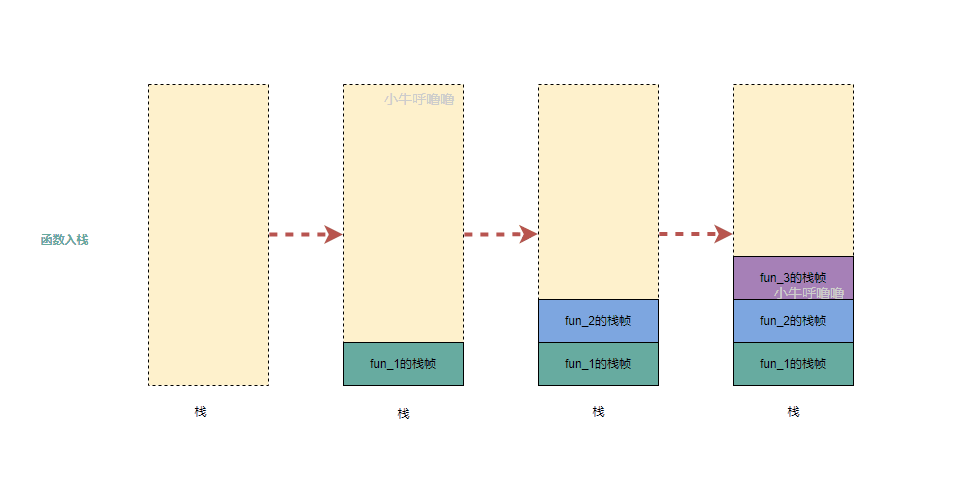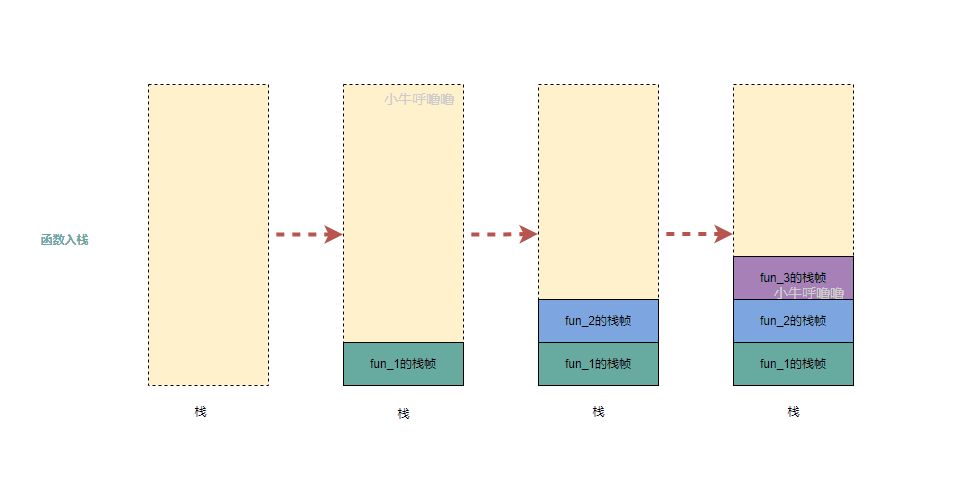
- 函数出栈的顺序
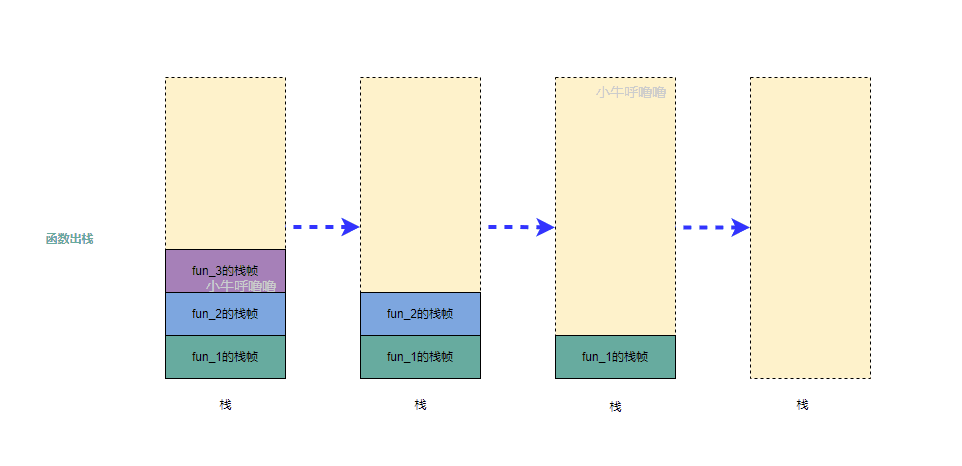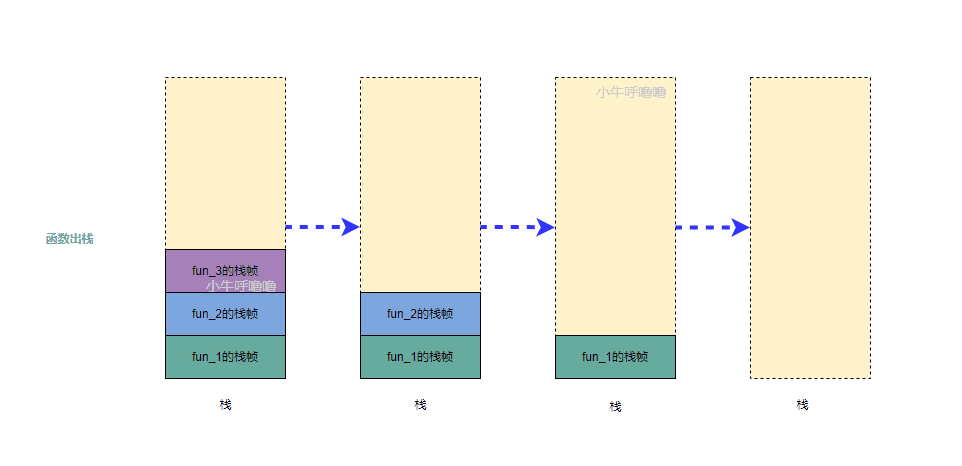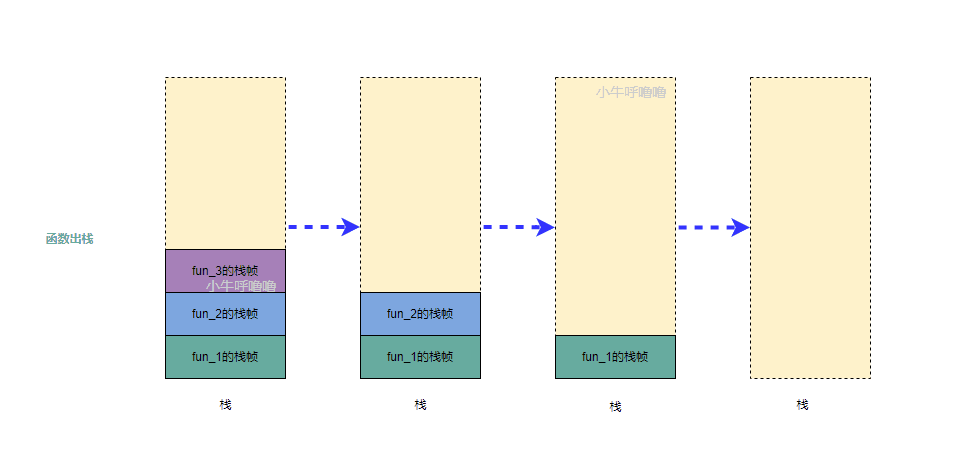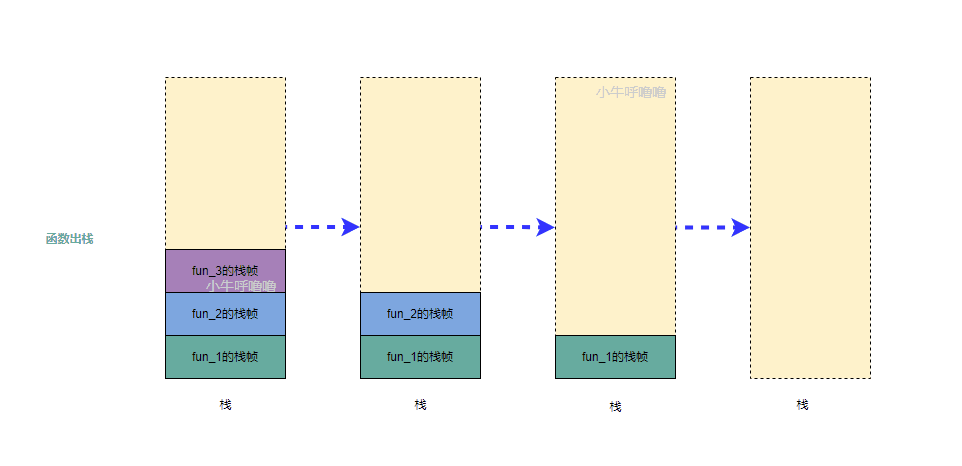
函数调用过程
有了上面这些知识的铺垫,我们就可以来具体看看函数调用过程中,究竟发生了什么变化
接下来以下面C语言的一段程序为例:
#include <stdio.h>
int sum (int a,int b)
{
int c = a + b;
return c;
}
int main()
{
int x = 10, y = 20, r;
r = sum(x,y);
printf("%d\n",r);
return 0;
}本例子在64位环境下执行的,我们需要了解一下寄存器的命名规则,比如rbp和ebp的区别就是一个是64位的,一个是32位的区别,那16位的一般表示为bp,但他们其实都是指同一个东西:ebp寄存器存放的是帧指针,指向当前的栈帧的底部
sum: # sum 函数入口
pushq %rbp # 保存旧的基址指针
movq %rsp, %rbp # 设置新的基址指针 (创建新栈帧)
movl %edi, -4(%rbp) # 将第一个参数 a 存入栈中 (地址 rbp-4)
movl %esi, -8(%rbp) # 将第二个参数 b 存入栈中 (地址 rbp-8)
movl -4(%rbp), %edx # 从栈加载 a 到 edx 寄存器
movl -8(%rbp), %eax # 从栈加载 b 到 eax 寄存器
addl %edx, %eax # eax = edx + eax (计算 a + b)
movl %eax, -12(%rbp) # 将结果存入局部变量 c (地址 rbp-12)
movl -12(%rbp), %eax # 将返回值 c 存入 eax 寄存器
popq %rbp # 恢复旧的基址指针 (销毁栈帧)
ret # 返回调用位置
.size sum, .-sum # 标记 sum 函数大小
.globl main # 声明 main 函数为全局可见
.type main, @function # 定义 main 为函数类型
main: # main 函数入口
pushq %rbp # 保存旧的基址指针
movq %rsp, %rbp # 设置新的基址指针 (创建新栈帧)
subq $16, %rsp # 分配 16 字节栈空间 (局部变量存储)
movl $10, -4(%rbp) # 初始化 x = 10 (地址 rbp-4)
movl $20, -8(%rbp) # 初始化 y = 20 (地址 rbp-8)
movl -8(%rbp), %edx # 加载 y 到 edx (准备第二个参数)
movl -4(%rbp), %eax # 加载 x 到 eax (准备第一个参数)
movl %edx, %esi # 第二个参数存入 esi (b = y)
movl %eax, %edi # 第一个参数存入 edi (a = x)
call sum # 调用 sum 函数
movl %eax, -12(%rbp) # 将返回值存入 r (地址 rbp-12)
movl -12(%rbp), %eax # 加载 r 到 eax (printf 参数)
movl %eax, %esi # 将结果存入 esi (第二个参数)
leaq .LC0(%rip), %rdi # 加载格式字符串地址到 rdi (第一个参数)
movl $0, %eax # 设置浮点参数数量为 0
call printf@PLT # 调用 printf 函数
movl $0, %eax # 设置 main 返回值 0
leave # 恢复栈指针 (等价于 movq %rbp, %rsp; popq %rbp)
ret # 返回操作系统
.size main, .-main # 标记 main 函数大小
.section .rodata # 只读数据段先来介绍一下概念,在汇编中,函数调用主要分为3个部分:调用前、调用中和返回。函数的调用是通过call指令完成的,执行call指令,会将返回地址压入栈中,再跳转到指定位置。返回过程则通过ret指令完成,它的作用是 将栈中的地址弹出到IP寄存器,然后跳转执行后续指令
另外函数调用的时候,我们常常会传递一个或者多个参数。返回时也要把返回值保存下来
我们来总结一下函数调用的一般过程,虽然不同型号的芯片、操作系统会有差别,但大致的流程基本类似:
- 创建栈帧:在函数调用前时,首先将
旧的基址指针压入栈中,然后设置新的基址指针,这个操作其实就是新栈帧的初始化 - 参数入栈:分配
16 字节栈空间 (用于局部变量存储),然后会给局部变量进行赋值并压入栈中,接着将函数调用时的实参按序依次压入栈中 - 返回地址保存再控制权转移:此时,CPU会执行到
call指令处,正式调用sum函数,实现从调用者到被调用者的控制权转移;需要注意一下,call会先把下一条指令的地址(即返回地址)入栈,再跳转到对应函数的起始地址处,执行被调用的函数;这样当函数执行完毕后,CPU才可以跳转回程序正确的执行位置。 - 函数执行:被调用函数
sum开始执行,同样还是执行pushq %rbp movq %rsp, %rbp,来创建新的栈帧,这里不是覆盖,而是再次压入栈中。分配必要的内存空间用于局部变量,并进行计算。在此过程中,所有需要保存的状态信息都存储在栈帧中。 - 函数返回:当函数执行完毕后,结果会被保存到
eax寄存器中,通过一系列出栈操作来还原寄存器中的值,移动esp到ebp位置,恢复调用前的状态;并且通过ret指令,并从栈顶弹出返回地址,CPU跳转到该位置继续执行程序,从而实现控制权的再次转移
至此一个标准的函数调用,完整过程就结束了,到这里我们可以发现,栈其实就是函数调用时的"载体",它存放这函数调用前、中、后各阶段,所需的各种各样的必要信息,也就是上下文的保存与恢复。
如果是递归调用,那么每次递归都会创建一个新的栈帧,并将返回地址压入栈中。递归结束时,栈帧自下而上回收,确保程序能够正确返回。普通函数调用与递归调用并没有本质的区别

参考资料:
https://en.wikipedia.org/wiki/Stack_(abstract_data_type)
Stack Data Structure - GeeksforGeeks
Functions and the Stack (Part 7)
感谢阅读,原创不易,如果有所收获的话,别忘了关注我!

作者:小牛呼噜噜
本文到这里就结束啦,感谢阅读,关注同名公众号:小牛呼噜噜,防失联+获取更多技术干货